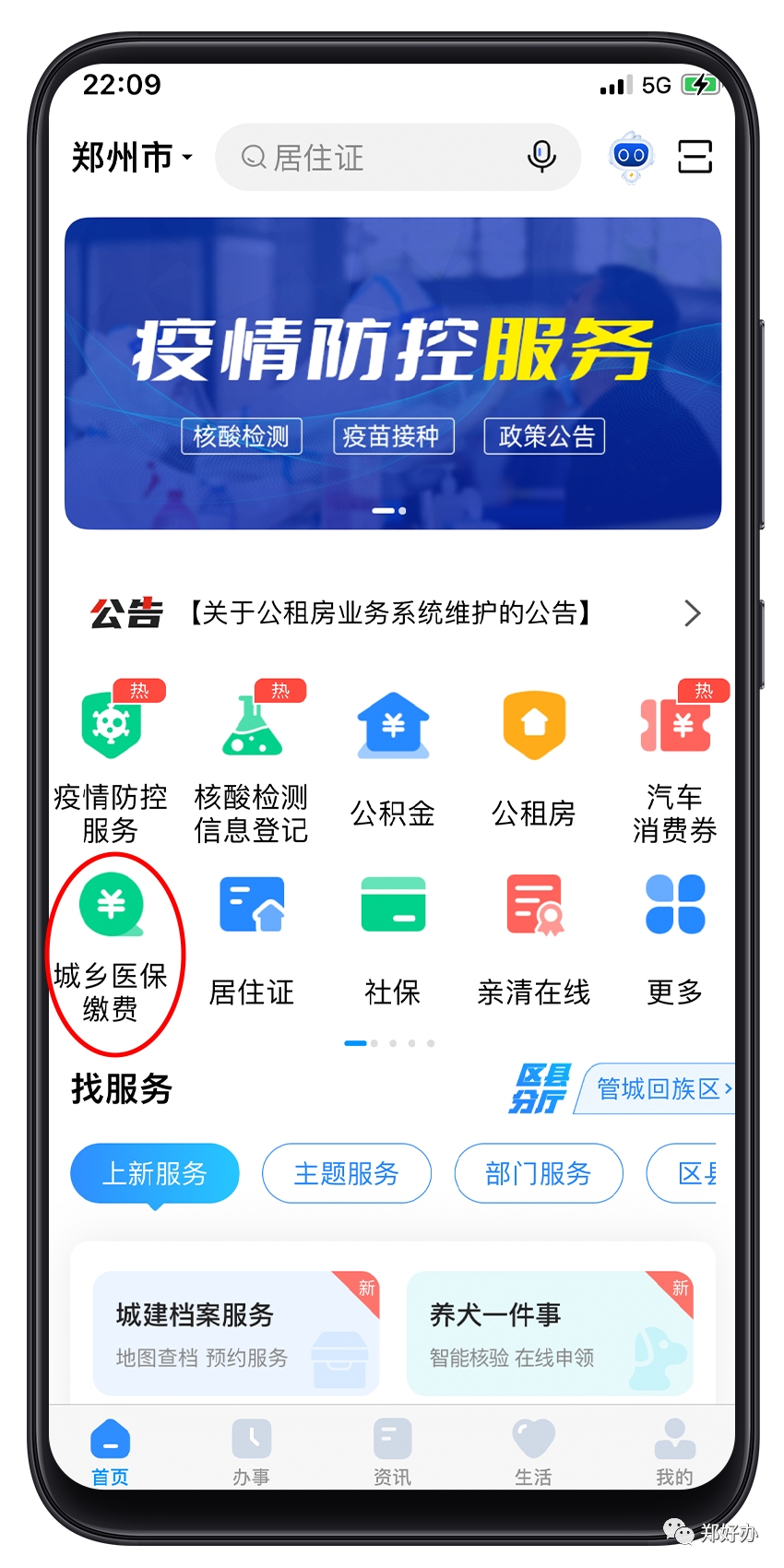
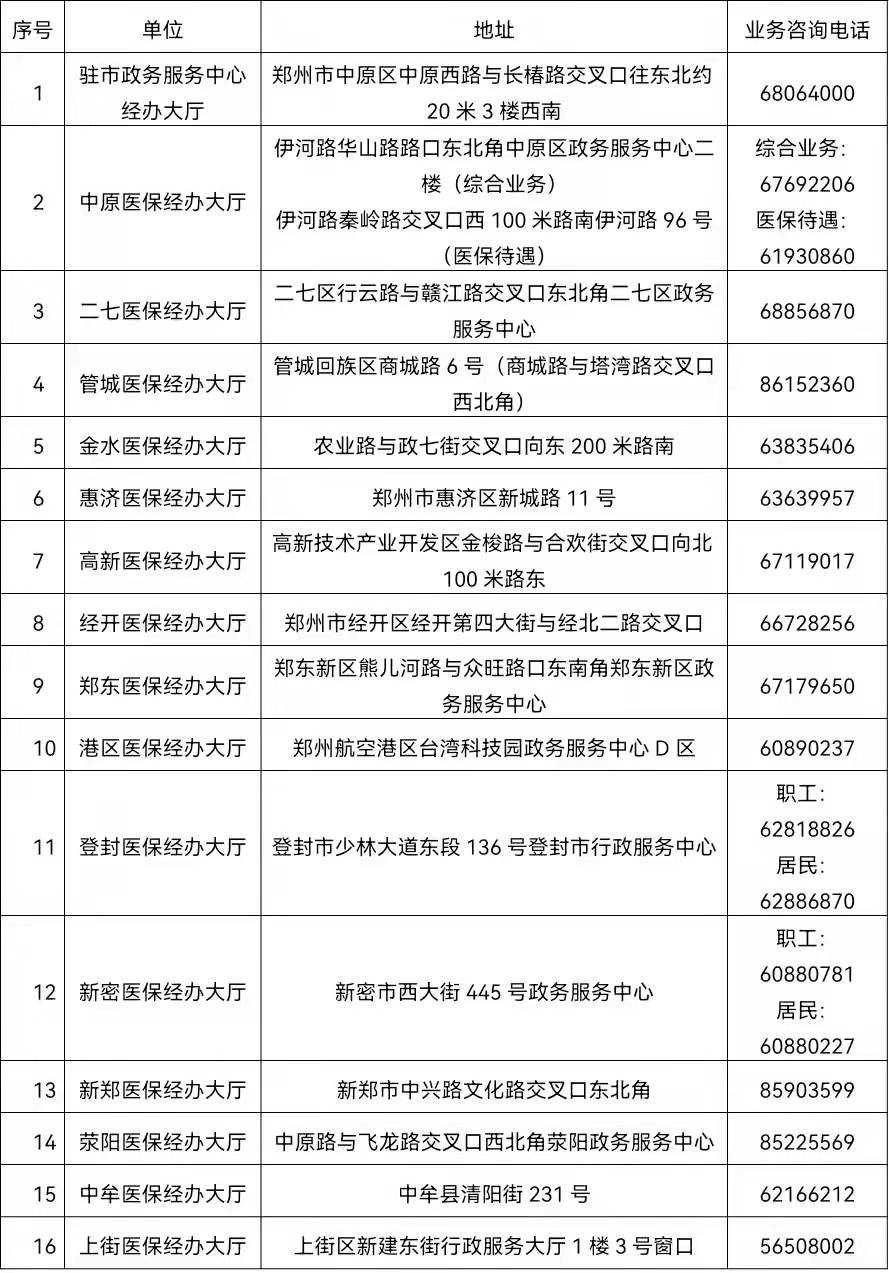
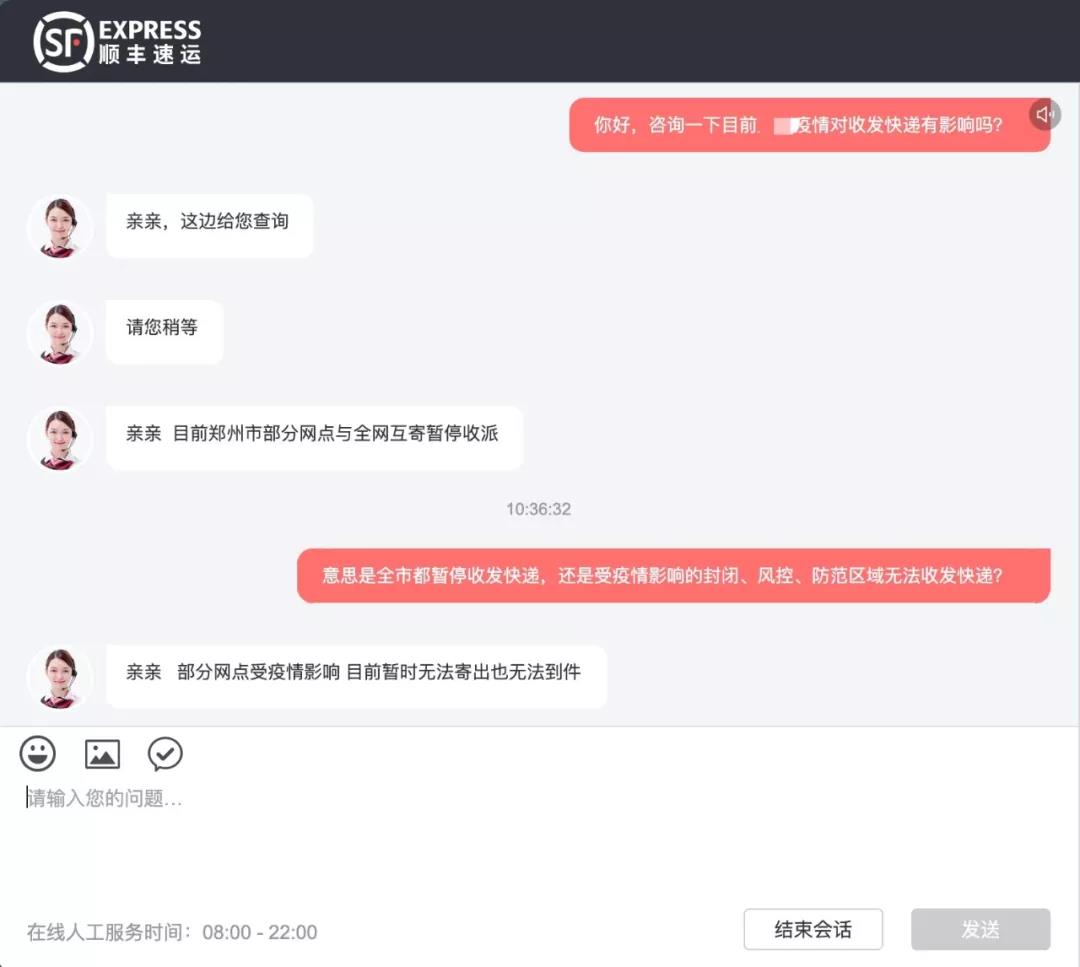
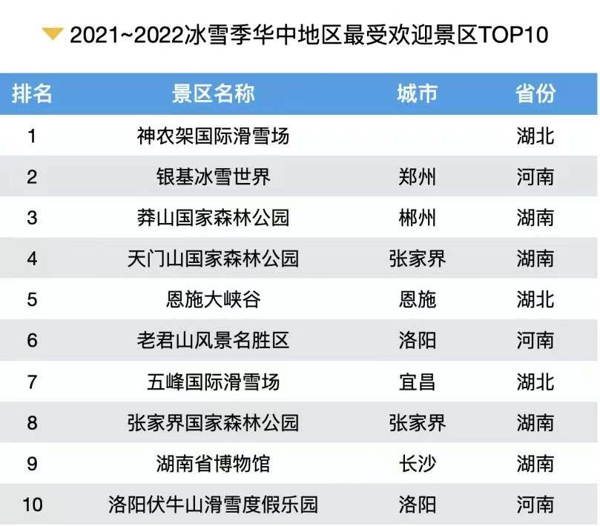
業界首個!記憶張量 × 商湯大裝置:國產GPGPU推理成本反超 A100-當前資訊
記憶張量科技有限公司與商湯科技大裝置團隊聯合宣布,成功在國產GPGPU集群上實現了業界首個以“記憶—計算—調度”一體化為核心的PD分離商用推理集群,并在真實生產環境中穩定運行。測試數據顯示,該方案綜合推理性價比達到同代英偉達A100的150%,標志著國產算力體系在大模型商業化落地方面首次具備了體系級競爭力。
此次突破為國產算力生態找到了差異化突破路徑。PD分離從硬件優化升級為記憶中心的設計范式。在MemOS體系中,分離架構可延伸至行為預測、上下文規劃、記憶布局等更高維度,成為整體架構的有機組成部分。這也預示著C端場景正式進入“記憶推理”時代。
 (資料圖)
(資料圖)
突破性能天花板
在過去一年中,“PD分離”(Prefill與Decode分離)已成為大模型推理優化的關鍵技術方向。然而,單純依靠硬件層面的隔離,其性能提升存在天然上限。隨著DeepSeek-R1等高性能模型從B端走向C端大規模應用,“記憶”已成為影響用戶體驗與成本結構的核心變量。
記憶張量旗下核心產品MemOS作為業內首個以記憶為中心的系統級基礎設施,創新性地將大模型認知結構劃分為參數記憶、激活記憶、明文記憶三類,形成了跨時間尺度的智能調度鏈路。該系統能夠精細決策哪些計算應前移至Prefill階段,哪些必須留在Decode環節,以及任務的保留、降級或淘汰策略。
“只有當PD分離與記憶結構深度耦合,重構‘記憶—計算—調度’整體體系,才有機會真正突破傳統性能上限。”記憶張量技術負責人表示。MemOS與PD分離的結合,本質上是為高速算力通道配上了一套精密的“交通指揮系統”,將分離架構的潛力發揮到極致。
從優化技巧到推理范式
本次合作中,商湯大裝置提供了系統級基礎設施支撐,其IaaS層高效算力池與智能調度能力為模型推理提供了穩定底座。Ignite框架則實現了多后端推理適配、KVCache優化、關鍵算子加速等性能增強,形成了完整推理優化鏈路。
算豐信息為集群提供了核心算力支持,管理所有高性能GPGPU計算資源、大規模存儲及高速互聯網絡,確保了PD分離架構的高效穩定運行。
在這一聯合架構中,MemOS的記憶體系映射為了清晰的物理分工:
P域(Prefill Domain) 成為“記憶工廠”,專注于影子上下文預測與KV Cache批量預生成,這類吞吐敏感型任務得以集中處理,不再干擾實時交互;
D域(Decode Domain) 則扮演“實時交互前臺”,專注于用戶請求解碼,確保首字生成時間(TTFT)的超低延遲;
跨節點KV Cache 通過高帶寬互聯與零拷貝路徑實現“即產即用”,MemOS的激活記憶機制與商湯大裝置的通信優化形成互補,極大降低了傳輸開銷。
“這是一次體系級的結構共振,”商湯大裝置架構師指出,“PD分離為MemOS提供了高速算力通道,而MemOS則為PD分離注入了精細到記憶單元的業務調度邏輯。”
全面超越傳統架構
在嚴格的生產級評測環境下(包括2k輸入、1k輸出、TTFT<2s的SLA約束、72小時穩態運行),該聯合方案交出了令人矚目的成績單:
集群整體吞吐量提升75%,從基礎部署的107.85 tokens/s躍升至189.23 tokens/s;單卡并發能力提升20%,從每卡25.00并發提升至29.42并發,顯著增強了C端高并發場景的承載能力;TTFT全程穩定小于2秒,Decode域因職責單一化而避免了資源搶占……綜合推理性價比達到同代英偉達A100的150%,在相同負載與SLA約束下實現了體系級正面超越。
“這些數據表明,國產GPU已不再只是‘能跑大模型’的替代選項,而是真正具備了承載R1級C端業務的體系能力。”記憶張量商業化負責人說。
打造記憶原生AI基礎設施
基于此次成功實踐,記憶張量與商湯科技計劃在以下方向深化合作:
一方面,將圍繞更大規模國產GPGPU集群,構建完整的記憶驅動流水線推理底座,形成“影子上下文—激活記憶—PD分離—多級緩存—AIOps”的可觀測、可演進基礎設施體系。
另一方面,雙方將在Prefill行為預測自治化、多級記憶管理、跨任務長時記憶一致性、Agent軌跡記憶等前沿方向持續探索,為伴隨式AI、具身智能及復雜任務編排提供支撐。
從更宏觀視角看,此次突破標志著國產算力體系正從“參數計算”走向“記憶計算”,從“靜態推理”走向“動態流水線”,從“模型中心”走向“記憶中心”。在AI技術快速演進的下半場,國產算力基礎設施不再僅是追趕者,更有機會成為下一代推理范式的定義者之一。
原標題:《業界首個!記憶張量 × 商湯大裝置:國產GPGPU推理成本反超 A100》
欄目主編:戎兵
本文作者:文匯報 沈湫莎
題圖來源:本報資料圖
 焦點熱議:中國石油簽署400.16億元合同 收購三家儲氣庫公司股權
焦點熱議:中國石油簽署400.16億元合同 收購三家儲氣庫公司股權